
0%
課程的尾聲,我們這期欲探討在實作 ML 與 DL 所面對的挑戰,想知道在過程中會面臨的困難及如何應對,趕緊往下閱讀文章吧~
課程即將進入尾聲,讓我們來談一談機器學習(ML)與深度學習(DL)實作過程中面臨的挑戰。回顧我們在第 9 堂課為您介紹的 ML 與 DL 工作流程,資料科學家必須遵循一系列反覆的步驟,從準備資料開始、然後開發、訓練、部署、評分和監測這個 ML 或 DL 模型。由於資料或所使用演算法的複雜性不同,一個模型從構思階段到實際上線可能需要數個月的時間,因此在專案初期您必須要對想要解決的問題有一個清晰的理解。此外,您還需要能夠確定這個專案預期的結果(或您想要得到的處方),也就是您期望這個模型能夠找出的見解 (Insights)。這項工作將迫使您更有效地決定如何準備您的資料,以及這個模型需要提供的最低預測精準度。只有在同時滿足業務需求與技術願景的前提下,您才能夠決定出一個最佳的作法。
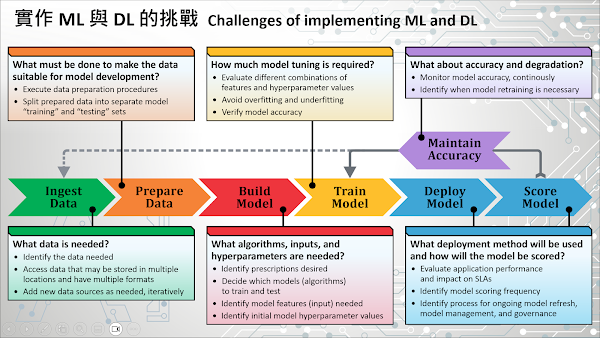
為了執行 ML 與 DL 專案,通常需要取得資料、匯入資料(例如匯入到資料庫),並在使用前進行必要的資料轉換。這個稱為“前置資料準備”的工作非常具有挑戰性,因為資料可能來自於任何地方,並以各種不同的格式儲存。在資料轉換過程中,必須從已取得的資料中挑選出有趣的事實 (Facts) 或特徵 (Features),這項工作被稱為“特徵工程 (Feature Engineering)”,而這個過程也可能相當耗費時間。學者的研究發現,在整個資料科學專案中,約 80% 的時間是花費在合併、彙整、格式化以及改變資料的形狀上。
只有當資料準備完成後,才能著手進行 ML/DL 模型的訓練。這個過程涵蓋選擇一組模型(演算法)進行訓練和驗證,然後透過準確性評估挑選出一個最佳的模型。通常,資料科學家會選擇“嘗試錯誤 (Trial and error)”的方式來找尋最佳模型,但這是一個耗時且重複的過程,同時需要大量的計算資源才能達成。
當最佳的模型被選定後,資料科學家會使用測試資料集(包含已知實際結果的新資料)進行測試,並透過評估模型的準確度來決定是否採用這個模型。理想情況下,資料科學家也會檢查模型,確保它不會發生“過度擬合 (Overfit)”或“低度擬合 (Underfit)”的問題。只有在完成這些工作後,經過訓練和測試的預測模型才可以真正被部署在正式營運系統環境中。
資料科學家如果決定要開發一個 ML/DL 模型,他們的最終目標是在企業的正式營運環境系統中部署這個模型,並利用它提供可靠的商業決策支援。模型部署 (Model Deployment) 是指將最終完成的模型整合到企業現有正式營運環境系統的過程,同時也是 ML/DL 生命週期的最後一個階段。然而,諷刺的是,模型部署卻是目前企業面臨的最大挑戰之一。專門從事機器學習模型導入的 Algorithmia 公司在他們 2020 年企業機器學習現況報告中發現,55% 受訪者並未真正將模型投入正式營運環境中使用。
為何模型部署這麼具有挑戰性?主要原因是因為模型本身通常只是大型應用系統的一小部分,因此單獨考慮模型部署是不夠的,必須在應用系統架構層面上進行規劃。這項工作需要跨越多個部門,包括資料科學家、IT 團隊、軟體開發團隊和應用系統使用者進行協調,以確保在不影響應用系統服務水準協定(SLA)的前提下,讓模型可靠地完成其工作。除此之外,ML/DL 模型無法順利完成部署,可能還包括以下的原因:
一般來說,Python 和 R 通常是建立和訓練 ML/DL 模型的主要程式語言,但這些模型有時會被移植到 C++ 或 Java 等程式語言中,藉以提高其互通性 (Interoperability) 與執行效能 (Performance)。然而,將模型從一種程式語言移植到另一種程式語言是有困難的。儘管容器化 (Containerization) 技術(如 Docker)可以解決相容性 (Compatibility) 和可攜性 (Portability) 的挑戰,但在相依性檢核 (Dependency checking)、錯誤檢核 (Error checking) 與測試 (Testing) 階段中仍然可能會遇到問題,進而導致失敗。
當我們談到深度學習 (Deep Learning),這意味著我們需要大量的 CPU,甚至是 GPU 運算能力來訓練和使用這些神經網路模型。如果將這些神經網路模型應用於企業的正式營運系統中,也需要同樣的運算能力來快速處理資料並提供即時運算與處理,以供大量使用者使用。然而,若企業的正式營運系統環境需要大量的 CPU 與 GPU 資源,這會讓部署任務增加額外的成本與複雜性。
針對經典的應用軟體開發與架構設計,愈完整的抽象化邊界 (Abstraction Boundaries),也就是使用封裝 (Encapsulation) 與模組化設計 (Modular design),可以有效隔離軟體功能模組,讓程式碼較容易進行修改與優化。可惜的是,對於 ML/DL 系統來說,我們很難嚴格地執行抽象化的邊界設計。事實上,較為複雜的 ML/DL 模型很難用軟體邏輯來表達其運作內容,這會影響模型的封裝與模組化,使它較不易與企業的應用系統進行整合。
在開發 ML/DL 專案的初期,資料科學家通常會使用可管理、相對靜態的資料集進行模型訓練與開發。然而,當模型被轉移到正式營運環境系統中,它必須處理更大量的資料。正因為這個理由,模型必須具有擴展性,以便能夠處理更多的可用資料,滿足應用系統和使用者的需求。
在正式營運系統環境中,一種簡單的模型部署方法是將訓練和測試過的模型儲存在系統設備的某個實體位置,讓系統使用者能夠讀取該模型檔案,並將其套用在他們自己的資料集上執行。然而,這種方法通常不可行,因為大部分的應用系統使用者無法直接存取正式營運環境系統設備(例如電腦上的某個資料夾),同時使用者也可能欠缺執行模型程式檔的技術能力。
因此,在實務上較常見的作法是將經過訓練和測試的模型設計為一個基於 REST (Representational State Transfer) 軟體架構的服務,REST 是一種經常被用於網頁服務架構 (Web Service Architecture) 的標準化溝通方法。符合 REST 架構風格的 Web 服務(稱為 RESTful Web 服務),可以在已連網環境的電腦系統之間提供互通性。在此架構下,一組被稱為 RESTful API(應用程式介面)的功能將使得應用程式開發人員更簡單地與該 Web 服務進行互動。透過 RESTful APIs 的功能,模型可以被運行在任何地方的應用系統呼叫使用,從而讓更多的使用者能夠使用到模型提供的功能。
要使用以 RESTful API 方式部署的模型,應用程式開發人員只需透過 API 將輸入資料傳送給模型服務,並且確保這些輸入資料與模型訓練時使用的資料相同(作為參數的特徵變數數量與格式需要一致)。接著,應用程式開發人員可以呼叫另一個 API 來取得模型服務產生的推論結果。模型產生的輸出通常被稱為推論 (Inference),因為模型透過輸入資料推斷出一個結果。如果模型可以產生一個分數,讓人能夠透過它做出決策,那麼這個過程也可以被稱為評分 (Scoring)。值得注意的是,模型推論可以在不同的伺服器上執行,並不一定要在訓練模型的那台伺服器上執行。實務上,我們通常會將模型推論伺服器擺放在靠近使用它的應用程式系統伺服器的附近,藉此降低因網路資料傳輸而損耗的資源。
還有一件重要的事,除了初始化部署,模型的稽核 (Auditing)、監控 (Monitoring)、更新以及系統維護才是真正具有技術性挑戰的工作,例如本課程開頭圖片中紫色箭頭 (Maintain Accuracy) 所示。當一個模型部署完成後,它必須持續受到監控,以確保其預測品質不會因時間的推移而降低。預測模型會因環境變化而導致預測性能惡化,例如,詐欺偵測模型可能因為詐欺手法的改變而失去精確度。因此,在正式營運環境中,為了維持模型的準確度,資料科學家必須使用新的資料重新訓練模型 (Re-training),以確保模型符合預期的品質目標。
備註:本文中提到的 Algorithmia 公司於 2021 年 7 月被機器學習預測分析平台 DataRobot 公司併購,因此「2020 年企業機器學習現況報告」目前已無法下載。
參考資料:無
