
0%
了解完工作流程後,緊接著將帶您了解模型的具體是什麼?一起接著看下去吧
儘管您需要投入大量時間來取得與準備機器學習(ML)和深度學習(DL)的資料,但誠如上一堂課所說,ML/DL 的大部分工作流程集中在建立、訓練、部署和監控“模型”上。如果您不是資料科學家,您可能不熟悉“模型”的概念。我們將使用本堂課試圖彌補這一點。
ML 和 DL 的本質可以總結為以下三點:
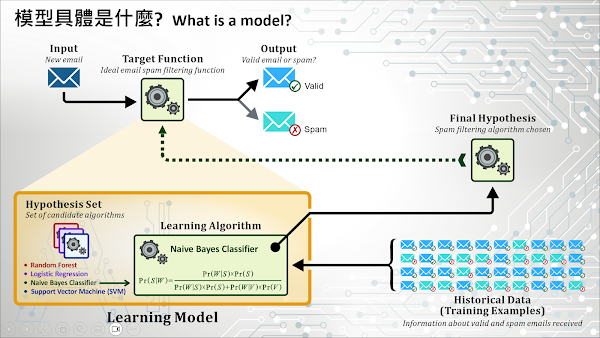
如果您曾使用過 Yahoo 或 Google 的電子郵件服務,您可能已經看過一個名為“Junk”或“Spam”的郵件資料夾。同時,如果您仔細檢查這個資料夾中的郵件,您應該會發現它包含了您並不真正想收到的郵件。如果您連續刪除來自同一個寄件者的郵件而不瀏覽郵件的內容,經過一段時間後,您可能會發現這個寄件者的郵件也會被自動歸類在“Junk”或“Spam”資料夾中。可以確定的是,這些電子郵件服務供應商使用了 ML 演算法來建立並運行一個可以過濾垃圾郵件的模型。以下我們就用這個例子,說明什麼是機器學習模型。
如上圖所示,一個學習模型 (Learning Model) 由兩個部分組成:第一個部分是資料科學家認為能夠用來尋找特定樣態(在本例中,用來區分垃圾郵件和正常郵件的樣態)的演算法清單;第二個部分則是從演算法清單中挑選出的實際演算法,這些演算法的選擇依據是基於它們經過訓練後,可以完成預期任務的機率。
一個機器學習模型通常包含兩個階段:「訓練階段 (Training Phase)」和「預測或評分階段 (Prediction or Scoring Phase)」。回到垃圾郵件過濾的例子,如果您仔細分析典型的垃圾郵件內容,您可能會發現包含“中獎”、“貸款”或“優惠”等詞彙。此外,這些詞彙可能並不常出現在我們認為有效的電子郵件中。在模型的訓練階段,我們會告訴我們的假說演算法組合 (Hypothesis Set of Algorithms) 檢視歷史郵件資料,並關注這些詞彙在垃圾郵件和有效郵件中出現的機率。
例如,假設我們有一個訓練資料集 (Training data set),包含 10,000 封郵件,其中 6,000 封屬於垃圾郵件。如果在這個訓練資料集中,“中獎”這個詞彙出現在 2,000 封垃圾郵件和 10 封有效郵件中,那麼垃圾郵件包含這個詞彙的機率為 0.333(2,000/6,000 = 0.333),而出現在有效郵件中的機率則為 0.0025(10/4,000 = 0.0025)。因此,如果您收到的郵件中包含“中獎”這個詞彙,那麼這封郵件被歸類為垃圾郵件的機率要比被歸類為有效郵件的機率高得多。
作為模型訓練階段的一部分,我們會使用假說演算法組合 (Hypothesis Set of Algorithms) 中的每一種演算法來計算機率,最後選擇出表現最佳的演算法作為我們的最終的假設演算法或模型。接著,我們會使用另一組測試資料集 (Test data set) 來驗證我們所選擇的模型。為了評估並比較模型的預測準確性,訓練資料集最好不要與測試資料集重複,這些資料都要盡可能接近真實資料 (Ground truth data)。
當然,一封電子郵件可能由數十或數百個單詞所組成,因此整個訓練過程需要使用更大量的詞彙來進行反覆運算。然而,您應該可以理解,我們的目標是在所提供的輸入(垃圾郵件會出現詞彙)未知的情況下,能產生出最高預測機率的演算法,也就是能夠有效判斷出垃圾郵件的比率。
